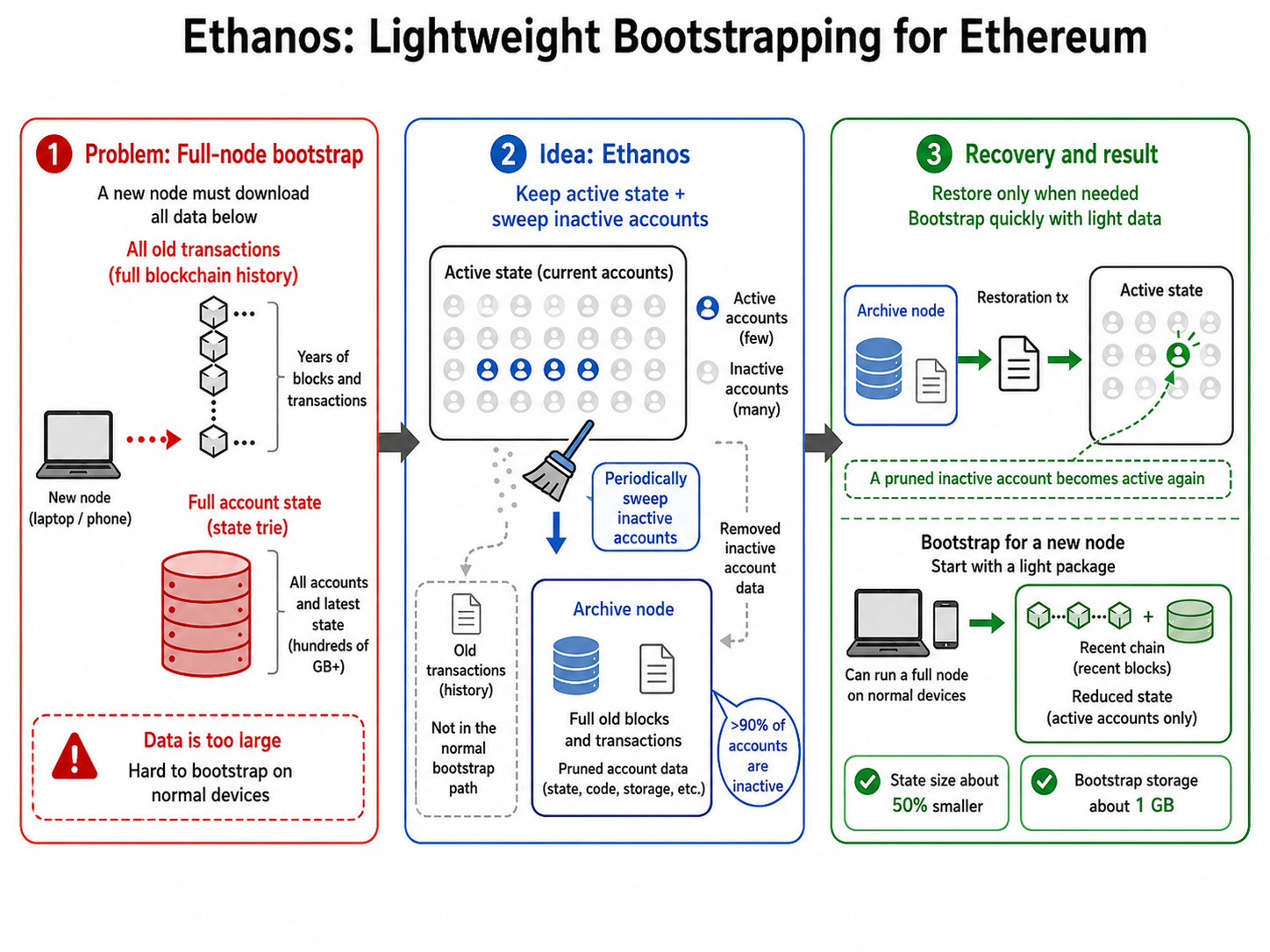
State Optimization
Account-based blockchains such as Ethereum suffer from severe scalability and synchronization overhead due to continuously growing state data.
This research focuses on efficient blockchain state management, including:
- Active-account Maintenance
- Reduction of Historical State Overhead
- Optimized Database Structures for Scalable Blockchain Storage Systems
Security and Privacy
Blockchain systems require strong guarantees for security, privacy, and trustworthiness in both on-chain and off-chain environments.
This research covers several topics, including:
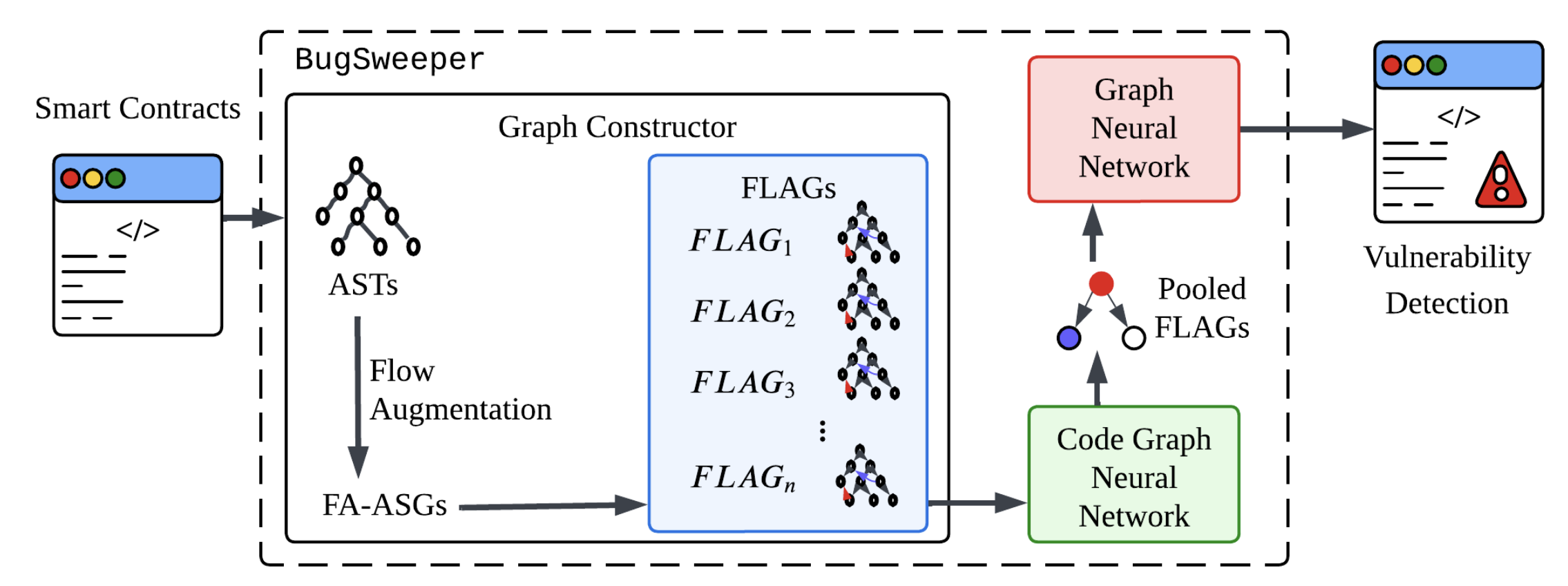
- AI-based Smart Contract Vulnerability Analysis (BugSweeper)
- Zero-knowledge Proof Systems
- Encrypted Mempool Protocols for Transaction Privacy
- Secure Off-chain Payment Protocols Based on Trusted Execution Environments (TEEs)